用 PyTorch Lightning 监控和串流 PyTorch 的训练进度
标签
AI
开发/云原生/Kubernetes
开发/Python/Notebook
开发/Python/PyTorch
开发/Python/PyTorchLightning
AI/PyTorch
AI/训练
AI/Tensorflow
AI/TensorBoard
开发/Python/TensorBoard
开发/Python/HuggingFace
AI/Trainer
AI/HuggingFace
AI/数据集/MNIST
字数
1949 字
阅读时间
12 分钟
这里以 PyTorch Lightning 为例子,跑 pytorch/examples 里面的 MNIST 这样的通用训练为例。
环境准备
克隆 pytorch/examples
shell
git clone https://github.com/pytorch/examples构建环境
shell
conda create -n demo-1 python=3.10安装依赖
shell
pip install lightning torch torchvision当前的 Python 依赖
txt
absl-py==2.0.0
aiohttp==3.9.1
aiosignal==1.3.1
async-timeout==4.0.3
attrs==23.2.0
cachetools==5.3.2
certifi==2023.11.17
charset-normalizer==3.3.2
filelock==3.13.1
frozenlist==1.4.1
fsspec==2023.12.2
google-auth==2.26.1
google-auth-oauthlib==1.2.0
grpcio==1.60.0
idna==3.6
Jinja2==3.1.2
lightning==2.1.3
lightning-utilities==0.10.0
Markdown==3.5.1
MarkupSafe==2.1.3
mpmath==1.3.0
multidict==6.0.4
networkx==3.2.1
numpy==1.26.3
nvidia-cublas-cu12==12.1.3.1
nvidia-cuda-cupti-cu12==12.1.105
nvidia-cuda-nvrtc-cu12==12.1.105
nvidia-cuda-runtime-cu12==12.1.105
nvidia-cudnn-cu12==8.9.2.26
nvidia-cufft-cu12==11.0.2.54
nvidia-curand-cu12==10.3.2.106
nvidia-cusolver-cu12==11.4.5.107
nvidia-cusparse-cu12==12.1.0.106
nvidia-nccl-cu12==2.18.1
nvidia-nvjitlink-cu12==12.3.101
nvidia-nvtx-cu12==12.1.105
oauthlib==3.2.2
packaging==23.2
pillow==10.2.0
protobuf==4.23.4
pyasn1==0.5.1
pyasn1-modules==0.3.0
pytorch-lightning==2.1.3
PyYAML==6.0.1
requests==2.31.0
requests-oauthlib==1.3.1
rsa==4.9
six==1.16.0
sympy==1.12
tensorboard==2.15.1
tensorboard-data-server==0.7.2
torch==2.1.2
torchmetrics==1.2.1
torchvision==0.16.2
tqdm==4.66.1
triton==2.1.0
typing_extensions==4.9.0
urllib3==2.1.0
Werkzeug==3.0.1
yarl==1.9.4修改代码
把 examples/mnist/main.py 里面的代码修改成使用 PyTorch Lightning 的 Trainer 的代码来跑。
python
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import pytorch_lightning as pl
from torch.utils.data import DataLoader
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
class LitNet(pl.LightningModule):
def __init__(self, lr):
super(LitNet, self).__init__()
self.save_hyperparameters()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
def training_step(self, batch, batch_idx):
data, target = batch
output = self(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
self.log('train_loss', loss)
return loss
def configure_optimizers(self):
optimizer = optim.Adadelta(self.parameters(), lr=self.hparams.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=0.7)
return [optimizer], [scheduler]
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, batch_size):
super().__init__()
self.batch_size = batch_size
def setup(self, stage=None):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
self.mnist_train = datasets.MNIST('../data', train=True, download=True, transform=transform)
self.mnist_test = datasets.MNIST('../data', train=False, transform=transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size)
def val_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)
def main():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--no-mps', action='store_true', default=False,
help='disables macOS GPU training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
use_mps = not args.no_mps and torch.backends.mps.is_available()
torch.manual_seed(args.seed)
if use_cuda:
device = torch.device("cuda")
elif use_mps:
device = torch.device("mps")
else:
device = torch.device("cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
model = LitNet(lr=args.lr)
mnist_data = MNISTDataModule(batch_size=args.batch_size)
# Trainer responsible for orchestrating the training
trainer = pl.Trainer(max_epochs=args.epochs)
trainer.fit(model, mnist_data)
if __name__ == '__main__':
main()python
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import pytorch_lightning as pl
from torch.utils.data import DataLoader
class LitNet(pl.LightningModule):
def __init__(self, lr):
super(LitNet, self).__init__()
self.save_hyperparameters()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def training_step(self, batch, batch_idx):
data, target = batch
output = self(data)
loss = F.nll_loss(output, target)
self.log('train_loss', loss)
return loss
def configure_optimizers(self):
optimizer = optim.Adadelta(self.parameters(), lr=self.hparams.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=0.7)
return [optimizer], [scheduler]
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, batch_size):
super().__init__()
self.batch_size = batch_size
def setup(self, stage=None):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
self.mnist_train = datasets.MNIST('../data', train=True, download=True, transform=transform)
self.mnist_test = datasets.MNIST('../data', train=False, transform=transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size)
def val_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
args = parser.parse_args()
model = LitNet(lr=args.lr)
mnist_data = MNISTDataModule(batch_size=args.batch_size)
# Trainer responsible for orchestrating the training
trainer = pl.Trainer(max_epochs=args.epochs)
trainer.fit(model, mnist_data)
if __name__ == '__main__':
main()开始训练
用
shell
python main.py就可以跑起来了。
跑起来的时候的效果
shell
~/pytorch-examples/mnist$ python main.py
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/home/neko/conda_envs/demo-1/lib/python3.10/site-packages/pytorch_lightning/trainer/configuration_validator.py:72: You passed in a `val_dataloader` but have no `validation_step`. Skipping val loop.
You are using a CUDA device ('NVIDIA GeForce RTX 4090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../../minst-data/data/MNIST/raw/train-images-idx3-ubyte.gz
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 9912422/9912422 [00:00<00:00, 102697917.04it/s]
Extracting ../../minst-data/data/MNIST/raw/train-images-idx3-ubyte.gz to ../../minst-data/data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../../minst-data/data/MNIST/raw/train-labels-idx1-ubyte.gz
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 28881/28881 [00:00<00:00, 81353723.19it/s]
Extracting ../../minst-data/data/MNIST/raw/train-labels-idx1-ubyte.gz to ../../minst-data/data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../../minst-data/data/MNIST/raw/t10k-images-idx3-ubyte.gz
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 1648877/1648877 [00:00<00:00, 81171481.52it/s]
Extracting ../../minst-data/data/MNIST/raw/t10k-images-idx3-ubyte.gz to ../../minst-data/data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../../minst-data/data/MNIST/raw/t10k-labels-idx1-ubyte.gz
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4542/4542 [00:00<00:00, 31333106.53it/s]
Extracting ../../minst-data/data/MNIST/raw/t10k-labels-idx1-ubyte.gz to ../../minst-data/data/MNIST/raw
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
-------------------------------------
0 | conv1 | Conv2d | 320
1 | conv2 | Conv2d | 18.5 K
2 | dropout1 | Dropout | 0
3 | dropout2 | Dropout | 0
4 | fc1 | Linear | 1.2 M
5 | fc2 | Linear | 1.3 K
-------------------------------------
1.2 M Trainable params
0 Non-trainable params
1.2 M Total params
4.800 Total estimated model params size (MB)
/home/neko/conda_envs/demo-1/lib/python3.10/site-packages/pytorch_lightning/trainer/connectors/data_connector.py:441: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=79` in the `DataLoader` to improve performance.
Epoch 13: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 938/938 [00:13<00:00, 71.67it/s, v_num=1]`Trainer.fit` stopped: `max_epochs=14` reached.
Epoch 13: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 938/938 [00:13<00:00, 70.69it/s, v_num=1]用 TensorBoard 查看训练进度
这个时候 MNIST 训练的目录下面应该会有 lightning_logs 目录可以观察数据,然后可以在另一个终端再打开一个界面,跑
shell
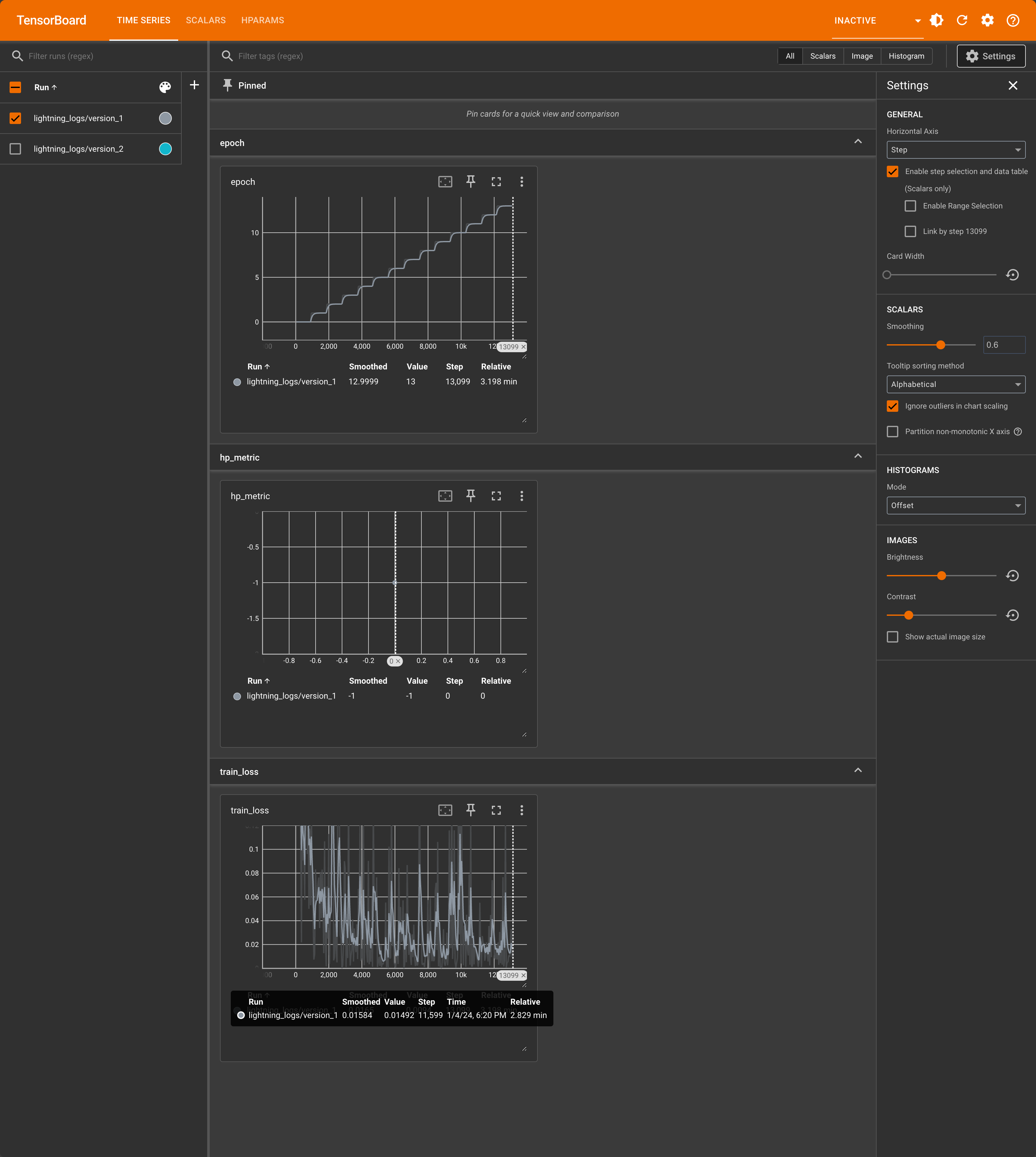
tensorboard --bind_all --logdir .就可以把 TensorBoard 起起来了:
TIP
如果没有安装 TensorBoard 的话可以通过
shell
pip install tensorboard原地直接安装。

额外补充
如果是用 Kubeflow 的 Notebook 然后需要额外添加 Port 来看 TensorBoard 的话,假设我的 notebook 叫做 neko-notebook 的话:
shell
$ sudo kubectl get notebooks
NAME AGE
neko-notebook 120m可以通过添加额外的 NodePort 类型的 Service 来实现:
shell
apiVersion: v1
kind: Service
metadata:
labels:
app: neko-notebook
name: neko-notebook-tensorboard-nodeport
spec:
ports:
- name: http
port: 6006
protocol: TCP
targetPort: 6006
selector:
app: neko-notebook
sessionAffinity: None
type: NodePort参考资料
延伸阅读
- Pytorch Lightning 和 HuggingFace 的 Trainer 哪个好用? - 知乎
- Tensorboard incorrect logging with DataParallel training · Issue #9839 · Lightning-AI/pytorch-lightning
 絢香猫
絢香猫