如何让 AI 玩 Minecraft?
标签
AI
游戏/Minecraft
AI/大语言模型/LLM
AI/强化学习/Reinforcement-learning/RL
AI/多模态/Code-as-policies
笔记/论文
字数
1157 字
阅读时间
6 分钟
主流方案
- 纯 LLM
- SPRING
- Voyager
- 基于强化学习
- DramerV3
- LLM 加持的强化学习
- Voyager
论文
Voyager | An Open-Ended Embodied Agent with Large Language Models
- [x] Watch @hu-po 大佬制作的解析视频:Voyager: LLMs play Minecraft (youtube.com)
- [x] Read MineDojo/Voyager: An Open-Ended Embodied Agent with Large Language Models
- [x] Read Voyager: An LLM-powered learning agent in Minecraft : r/MachineLearning (reddit.com)
- [x] Read MindAgent: Emergent Gaming Interaction,HTML 版本
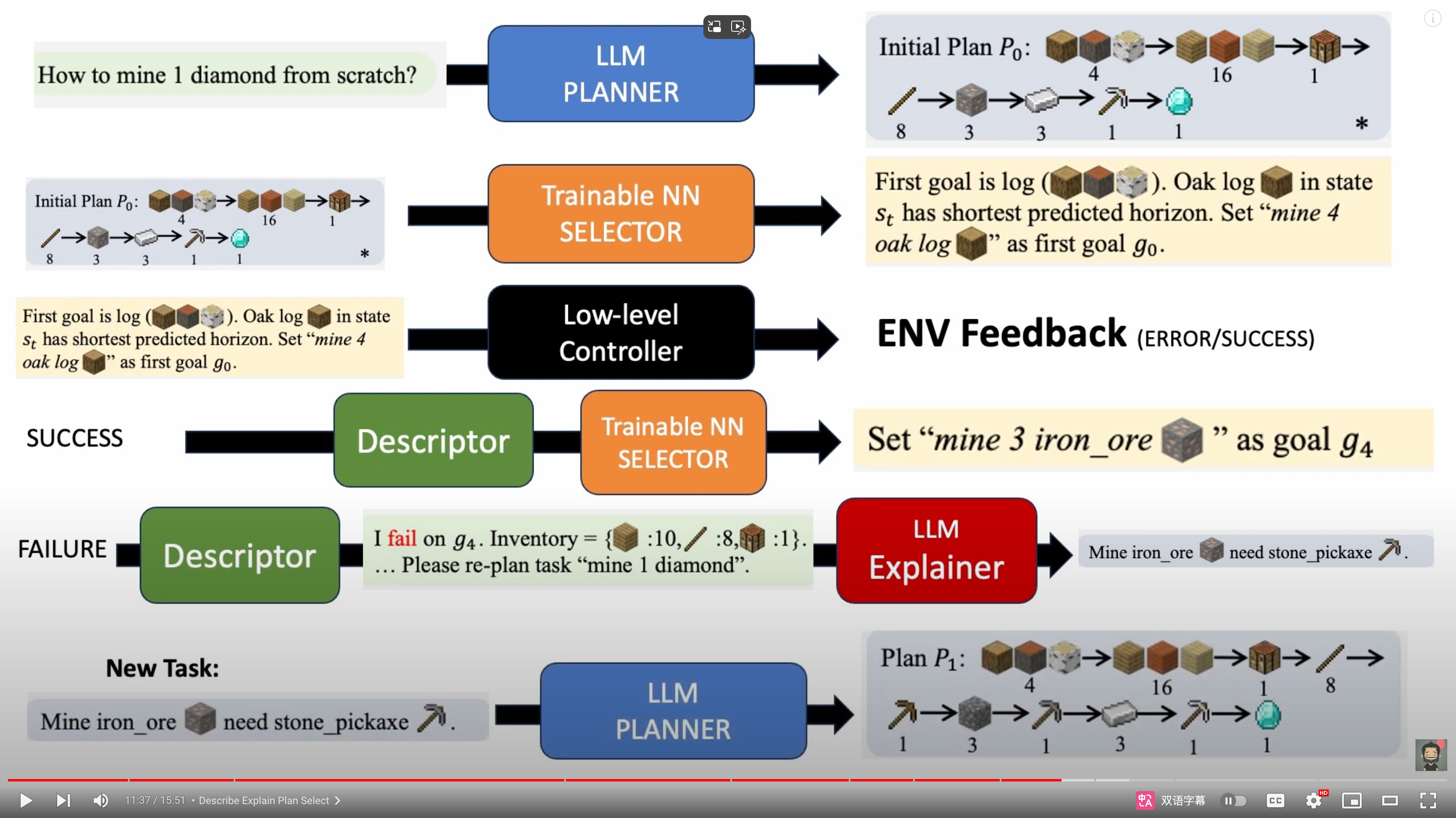
Voyager 更像是一个 Minecraft 游戏操作 API 调用的代码的代码生成器
- 它会通过 GPT4 生成不同的操作的调用代码。
- 比如如果要建造一个钻石剑,就是直接生成通过 MineDojo 包装的 API 的代码,包装成一个
createDiamondSward函数,等下次需要的时候就直接调用了。 - 所以事实上 Voyager 是穷举 Minecraft 游戏行为的 Agent,然后把结果和可以用的过程体现为一组函数,也就是论文中提到的 resuable skill set。
- 或者说 Code as action。
读后感受
- 😱 这里面会有一些机器学习或者强化学习的坑,比如事实上包括 Voyager 和其他的类似的 Planning Agent 都是站在「人类行为」的假设上进行的
- 💡 分享到了另外的一个 2304.03442 Generative Agents: Interactive Simulacra of Human Behavior 论文,这篇论文把大佬说服了认为我们可能活在模拟程序中,HTML 版本
- ❓ 有一个比较有趣的思考是:和 MineDojo 这样的 Minecraft API 调用环境不同的是,其实如果我们期望在现实世界中给机器人(robotics)添加 LLM 的 code generation 能力,我们的机器人是不会获得任何的可以用于 CoT 的错误的,因为现实世界中不会返回错误,它更不可能有一个像是 API 调用一样的文本形式的错误可以让我们以文本的形式输入给 LLM
- ❓ Voyager 的实现中提到的 Nearby Entities 是一个非常明确的,Agent 本身自己会知道的精确的地址的游戏对象,比如如果旁边 32 块内有一个僵尸,那么 Agent 会通过 API 的形式直接知道有僵尸,以及僵尸在什么地方,这个实现和 OpenAI 的 DOTA Bot 类似,DOTA Bot 就是建立在对游戏内对局状态的非常全面的了解之上的。但是对于人类玩家而言我们是不会知道的,通常我们如果屏幕中看不到僵尸的话要么是能听到,要么是小地图上能看到。
- 拓展:
Plan4MC
- [ ] Read 解析视频:LLM论文分享--我的世界的智能体代理Plan4MC,大语言模型给AI智能体做技能规划 - bilibili
- [ ] Skill Reinforcement Learning and Planning for Open-World Long-Horizon Tasks
- [ ] PKU-RL/Plan4MC: Reinforcement learning and planning for Minecraft.
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
实现
- LLM 如何参与进来
- 会用文本的形式描述 LLM 当前屏幕上的状态,比如
- 你现在看到了
- 西边,距离 1 步,有草
- 北边,距离 6 步,有树
- 你现在面向草
- 你现在的状态
- 血量:9/9
- 饥饿:9/9
- 你现在看到了
- 然后 LLM 会被要求输出接下来期望的状态,由对应的代码执行
- 会用文本的形式描述 LLM 当前屏幕上的状态,比如

2109.06780 Benchmarking the Spectrum of Agent Capabilities,HTML 版本
2305.15486 SPRING: Studying the Paper and Reasoning to Play Games,HTML 版本
2302.04449 Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals,HTML 版本
社区和资源
工具
- Minecraft 接口
- Other Minecraft Interfaces — MineRL 0.4.0 documentation
- MineDojo | Building Open-Ended Embodied Agents with Internet-Scale Knowledge
强化学习
openai/gym: A toolkit for developing and comparing reinforcement learning algorithms.已经挪到 Farama-Foundation/Gymnasium: An API standard for single-agent reinforcement learning environments, with popular reference environments and related utilities (formerly Gym) 去维护了
 絢香猫
絢香猫